這是換透過分析 Instagram API,取得所有圖片和影片
根據上一篇 Instagram Crawler with selenium (ruby 爬蟲) 會有幾個問題
- 因為是操作 browser 所以跟網路速度會有關係,萬一網路斷線或是很慢的話就沒辦法那麼順利爬取
- 頁面上的 class 都是亂數,可能是透過編譯自行產生,因此下次 Instagram 重新編譯,可能所有的 class 名稱又都不同了..
因此這次換用 API 的方式來爬取 Instagram 的貼文,因為是用 API 所以也不需要去操作 browser,取得對應的 class,也就不會有上述的問題!
Think
分析 API
首先先觀察一下 Instagram 上面的 API https://www.instagram.com/marvel/ (隨便一個都可以)
可以發現每次進到頁面會 request 三條 API,打開後發現其中一條 API,裡面有我們要的資訊 (edges 就是 API 取回的貼文)
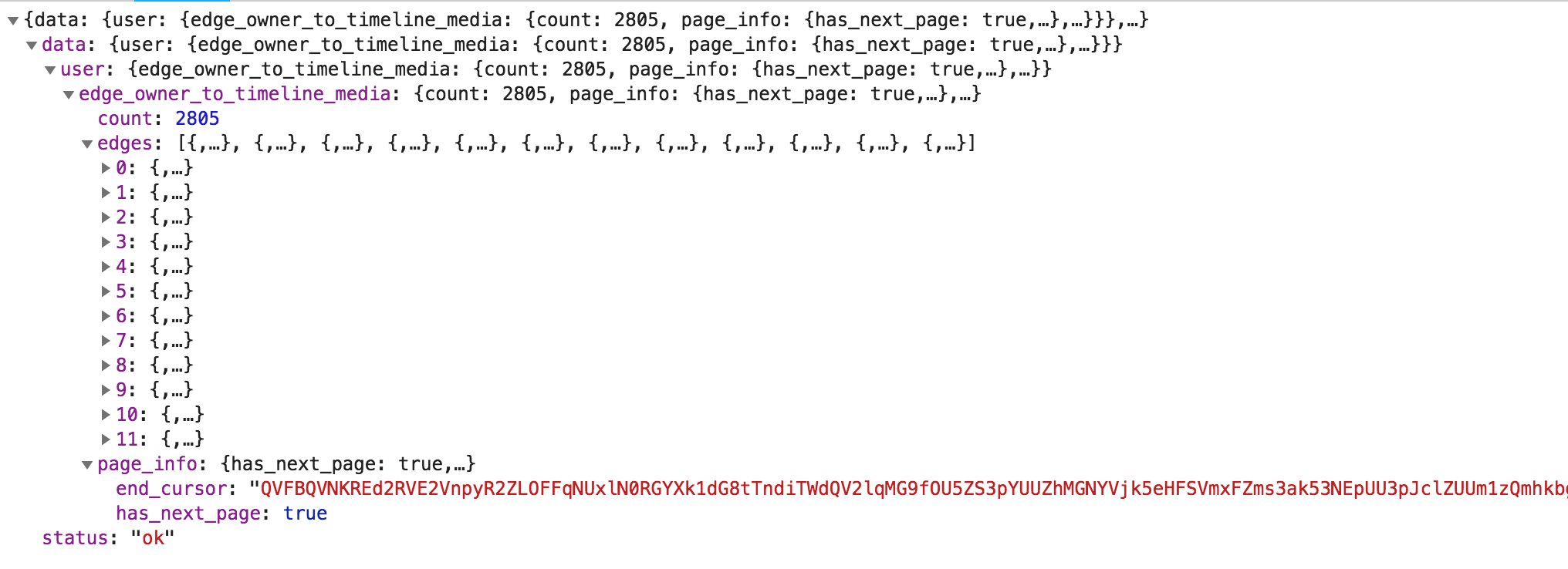
開始分析裡面的資訊,首先是 API

會發現後面都會帶兩個參數 query_hash & variables 而 variables 裡面是一個 json 又包了很多資訊
1
2
3
4
5
| {
"id":"204633036",
"first" 12,
"after": "QVFEeDUzd05jNVczMXpMRTNwYzlnYldCM0p4SGIyRmh4Q2VHYy1jZm1sUlRSalY3cVdoUklKWWdBT2RNSjJxc1pZbVBGZlN1REdjUExLMGlOWDhpR0VTcQ=="
}
|
- id: 研判應該是 user_id 之類,用來判斷使用者,因為所有 API 所使用的 id 都一樣
- first: 嘗試更換 first 的數字,就可以發現可以要到更多資料,應該是取得數量的設定
- after: 後面的參數,跟 API 裡面的
end_cursor 長度格式都是一樣,研判是用來判斷下一個 API 的參數所用,在 API 裡面還有一個參數是 has_next_page,因此可以確定 has_next_page 是用來判斷是否有下一頁,end_cursor 是下一頁所需要的參數值
1
2
3
4
| page_info": {
"has_next_page": true,
"end_cursor": "QVFDbml1aFJVRkM2QkVJdzRIN1pJTEpMVlpVTl9hdHh0YlBXUDZGRDRDa1NYLUpvX3hBaGlDcXNLSlhud0dma1hBWnNyOG5DWEFjNTNlOEJibXdyaml4Vg=="
}
|
嘗試將 API 上的 variables 裡的 end_cursor 換成 API 取回來的 end_cursor
Request 取得新貼文成功!
1
| https://www.instagram.com/graphql/query/?query_hash=50d3631032cf38ebe1a2d758524e3492&variables=%7B%22id%22%3A%22204633036%22%2C%22first%22%3A12%2C%22after%22%3A%22QVFDbml1aFJVRkM2QkVJdzRIN1pJTEpMVlpVTl9hdHh0YlBXUDZGRDRDa1NYLUpvX3hBaGlDcXNLSlhud0dma1hBWnNyOG5DWEFjNTNlOEJibXdyaml4Vg%3D%3D%22%7D
|
第一個 API?
接著會發現,每個 API 給的都是下一條 API 的 end_cursor,那第一條呢???
如果希望讓爬蟲自動去爬所有的貼文,而不是還要餵食第一條 API 給它..勢必還是要找到啊..
一開始怎麼找都找不到,最後終於在頁面原始碼找到了 (command + F end_cursor)
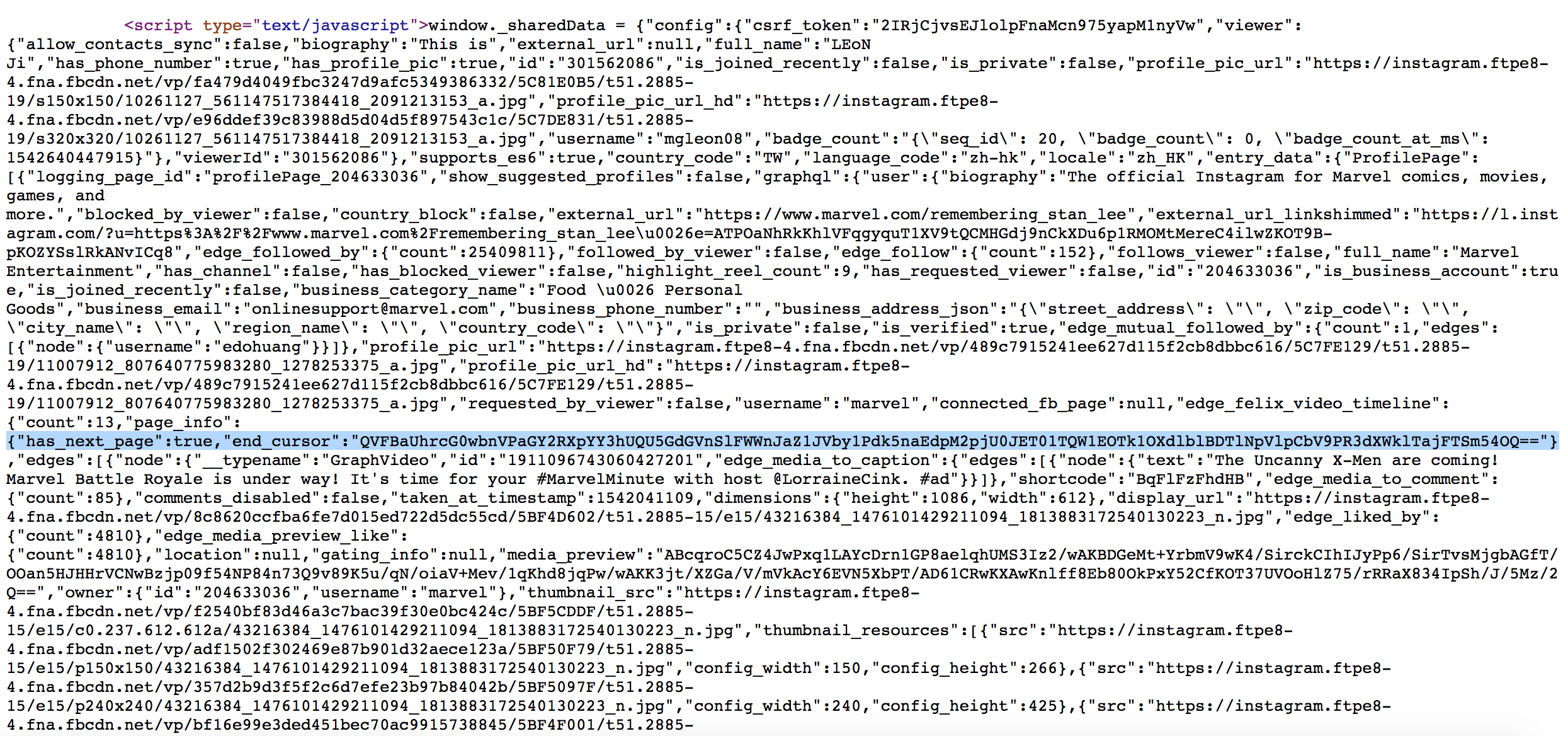
仔細觀察,發現都是包在 window._sharedData 裡面,因此第一條 API 的 end_cursor 就透過爬頁面的 window._sharedData 將參數帶到之前的 API 即可!
1
2
| doc = Nokogiri::HTML(html)
js_data = doc.at_xpath("//script[contains(text(),'window._sharedData')]")
|
前 12 個貼文?
再來會發現,我們已經取得了第一個 API,但是回來的資料,卻是從第 13 個貼文開始,而不是第一個??
原來第一個 API 會是從第 13 個貼文開始,而前 12 個貼文,在剛剛頁面的 window._sharedData 就可以找到!
分析後,如果前面 12 個有包含 video 或是 post,就沒辦法取得影片跟後面的連續圖片,仔細想想在這頁面也並不需要這兩種資訊,於是點貼文之後,會發現 video 和 post 連續圖片就跑出來了
Video 會發現在 property="og:video" 裡面

Post 則會在 "edges" 底下的 array 裡面
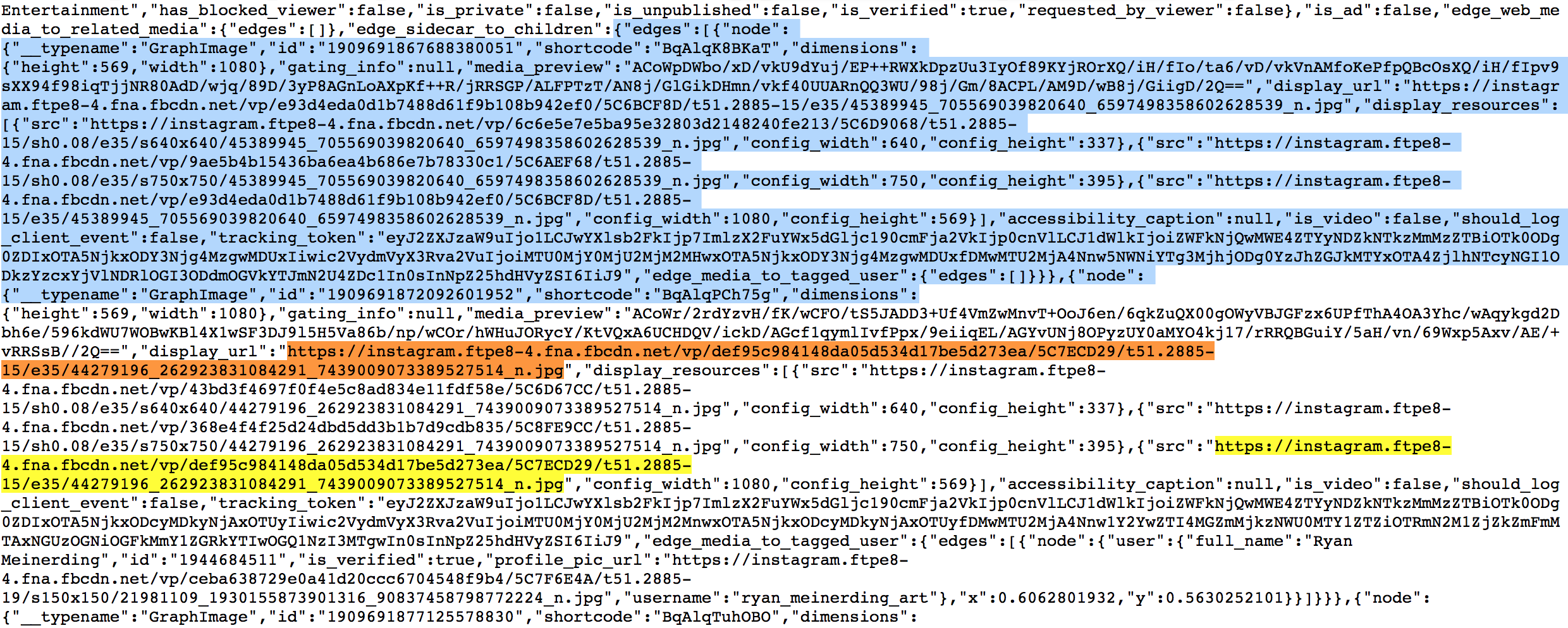
那要怎麼知道貼文的連結?仔細觀察貼文的 url 都是 https://www.instagram.com/p/BqAlq0wh9wV/ 看起來只要得到後面那段亂碼,就可以取得連結,接著就來看看
window._sharedData 裡面是否找得到
command + F BqAlq0wh9wV,就可以找到 shortcode":"BqAlq0wh9wV",判斷 shortcode 應該就是每個貼文的代碼,這樣就可以進到每個頁面,各自取得相關的資訊
策略
由上面分析過後,我們的策略就是前 12 個貼文,透過爬 html 來取得,第 13 個貼文開始,就透過 API 來取得!
Data
資料基本上都是在 edges 的 node 裡面
HTML
1
2
3
| # json = window._sharedData 裡面內容
page_info = json["entry_data"]["ProfilePage"][0]["graphql"]["user"]["edge_owner_to_timeline_media"]['page_info']
edges = json["entry_data"]["ProfilePage"][0]["graphql"]["user"]["edge_owner_to_timeline_media"]["edges"]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| edges.each do |edge|
node = edge["node"]
page_url = "https://www.instagram.com/p/#{node["shortcode"]}/"
if node["is_video"]
# VIDEO
url = Html.new(page_url).video_page
else
shortcode_media = Html.new(page_url).photo_page
if shortcode_media.is_a? Array
# POST
shortcode_media.each do |post|
url = post["node"]["display_url"]
end
else
# PHOTO
url = shortcode_media
end
end
end
|
1
2
3
4
5
| def video_page
doc = Nokogiri::HTML(html)
meta_v = doc.at_xpath("//meta[@property='og:video']")
url = meta_v.attribute_nodes.last.value
end
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def photo_page
doc = Nokogiri::HTML(html)
js_data = doc.at_xpath("//script[contains(text(),'window._sharedData')]")
json = JSON.parse(js_data.text[21..-2])
shortcode_media = json["entry_data"]["PostPage"][0]["graphql"]["shortcode_media"]
if shortcode_media["edge_sidecar_to_children"]
# POST
shortcode_media["edge_sidecar_to_children"]["edges"]
else
# PHOTO
shortcode_media["display_url"]
end
end
|
API
1
2
| page_info = json["data"]["user"]["edge_owner_to_timeline_media"]["page_info"]
edges = json["data"]["user"]["edge_owner_to_timeline_media"]["edges"]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| edges.each do |edge|
node = edge["node"]
if node["is_video"]
# VIDEO
url = node["video_url"]
elsif !node["edge_sidecar_to_children"].nil?
# POST
posts.each do |post|
url = post["node"]["display_url"]
end
else
# PHOTO
url = node["display_url"]
end
end
|
Ruby Gem
以上是 Instagram 爬蟲邏輯和概念,最後這邊做成一個 gem 可以直接使用!
{kind=link}