透過模擬瀏覽器行為,取得 Instagram 所有圖片和影片!
一般常見的 crawler,只要透過 http request,把 html 拉回來,就可以直接爬上面的原始碼
但現在很多網頁都是透過 frontend 透過 API 拉資料,在用 javascript 去做動態 render,導致直接拉 html 也拉不到什麼東西。
因此改用模擬 browser 的行為,讓它將 html 都長出來,再去爬裡面的資料。
selenium
A browser automation framework and ecosystem
簡單的來說就是可以透過程式,直接驅動瀏覽器進行各種網站操作,透過這個 WebDriver 就可以讓頁面長出資料後,再把要的資料爬出來!
WebDriver
一開始要先安裝 WebDriver,根據你要用的 browser 去安裝對應的 WebDriver,像我基本上都是用 Chrome,因此就要去安裝 ChromeDriver,比較簡單方式是直接執行
1
| |
Think
接著就開始分析要如何透過它來爬 instagram 頁面,這裡就用比較常用的 ruby 來講解。
用 ruby 來爬的話首先都會想到用 nokogiri,之前也有介紹過 用 Ruby 做網頁爬蟲,但這次必須模擬 browser 行為,因此改用 watir,watir 是一個已經整合 selenium 的 ruby gem,那現在來開始了。
首先先隨便找一個頁面來觀察,
一. 關閉不需要的區塊
1 2 | |
一開始會開一個全新的頁面,沒有 login,這時候下方會有個 login 的區塊,先找出關閉的button,並先將其關閉(避免影響瀏覽器操作)
1 2 3 4 | |
二. 解析
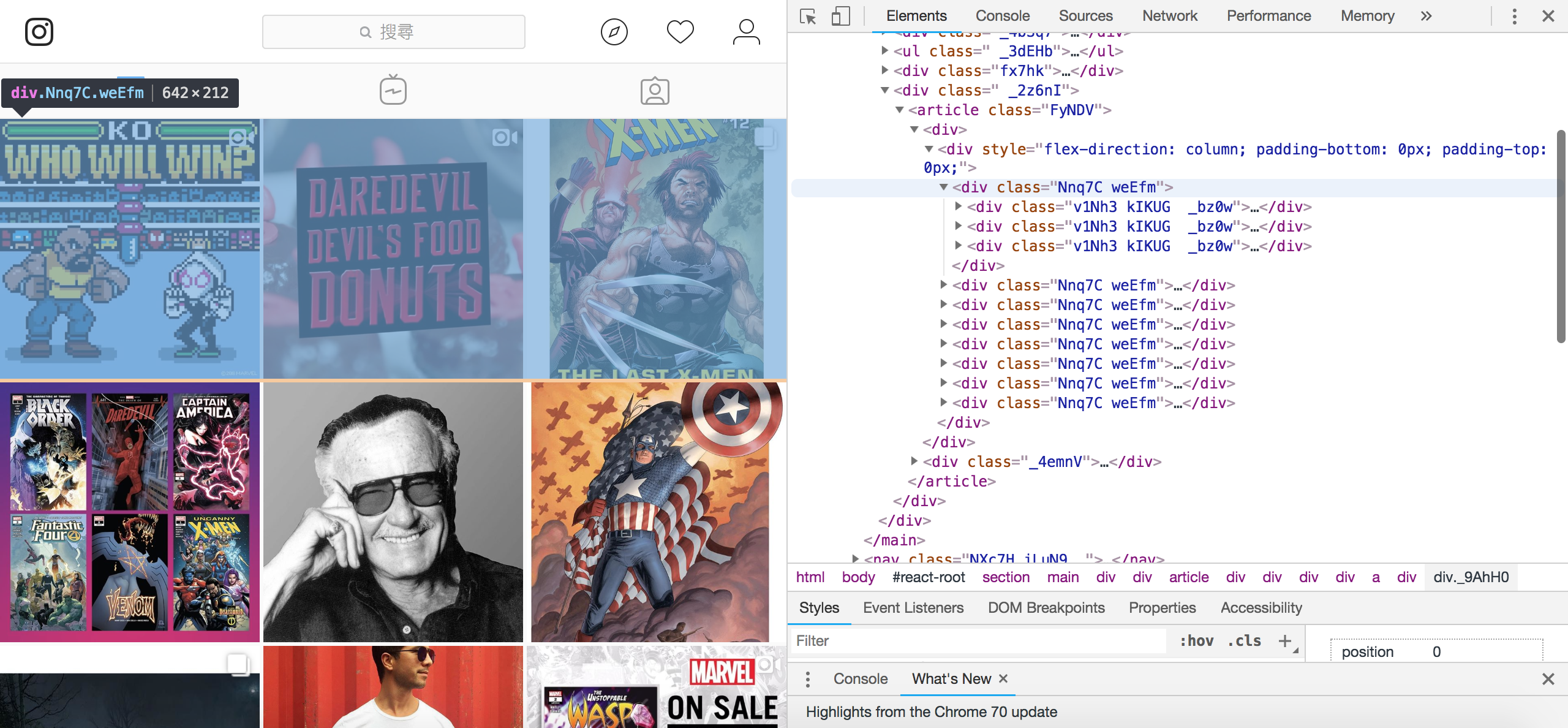
接著觀察在 instagram 裡面,每一行<div class="Nnq7C weEfm"></div>都有 3 個 po 文 <div class="v1Nh3 kIKUG _bz0w"></div>,而每個貼文的資訊就在 裡面,因此我們要的資訊都會在這裡頭
1 2 | |
裡面的資訊又分為 Photo, Video, Post,那要怎麼分辨這三個?
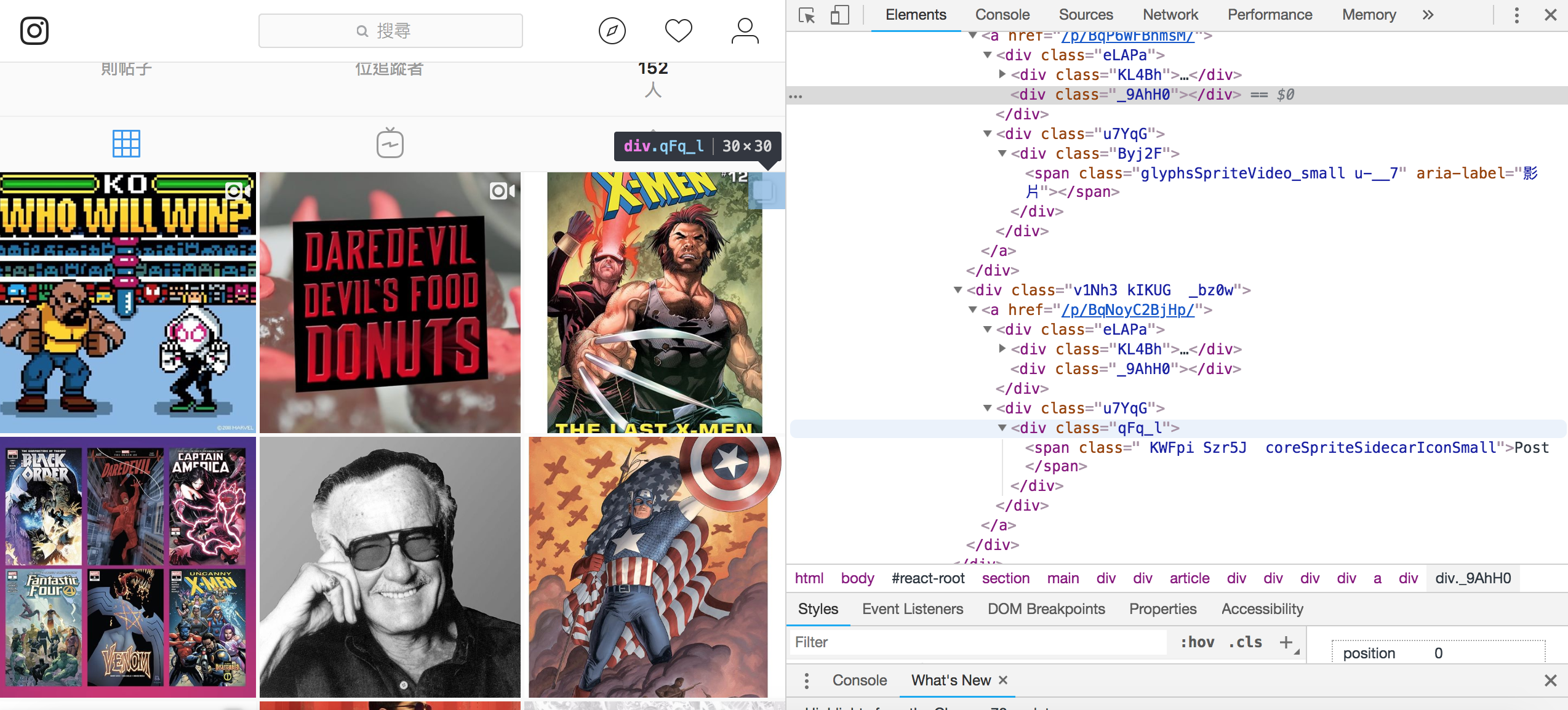
首先注意到右上角除了單一 Photo,就會有個 icon,再仔細看 Video 跟 Post 的 icon 的 class 不同,所以判斷就如下
- Photo: 沒有
<div class="u7YqG"></div> - Video: 有
<div class="u7YqG"></div>,並且裡面有<div class="Byj2F"></div> - Post: 有
<div class="u7YqG"></div>,並且裡面有<div class="qFq_l"></div>
接著知道在哪後就要取得對應資訊
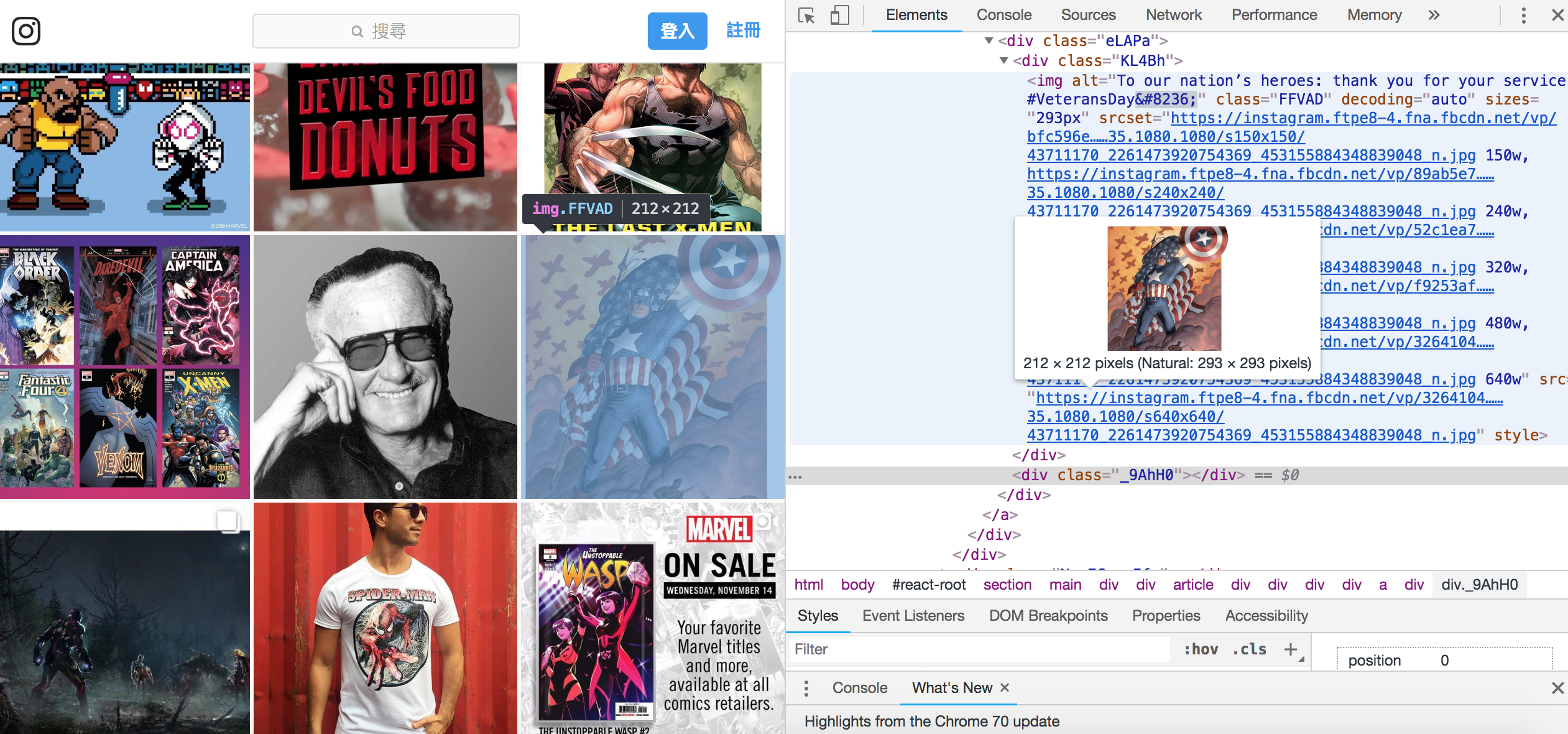
Photo
找到對應的 div 之後,取得 div 底下 image 的 src 即可。
1 2 | |
Video
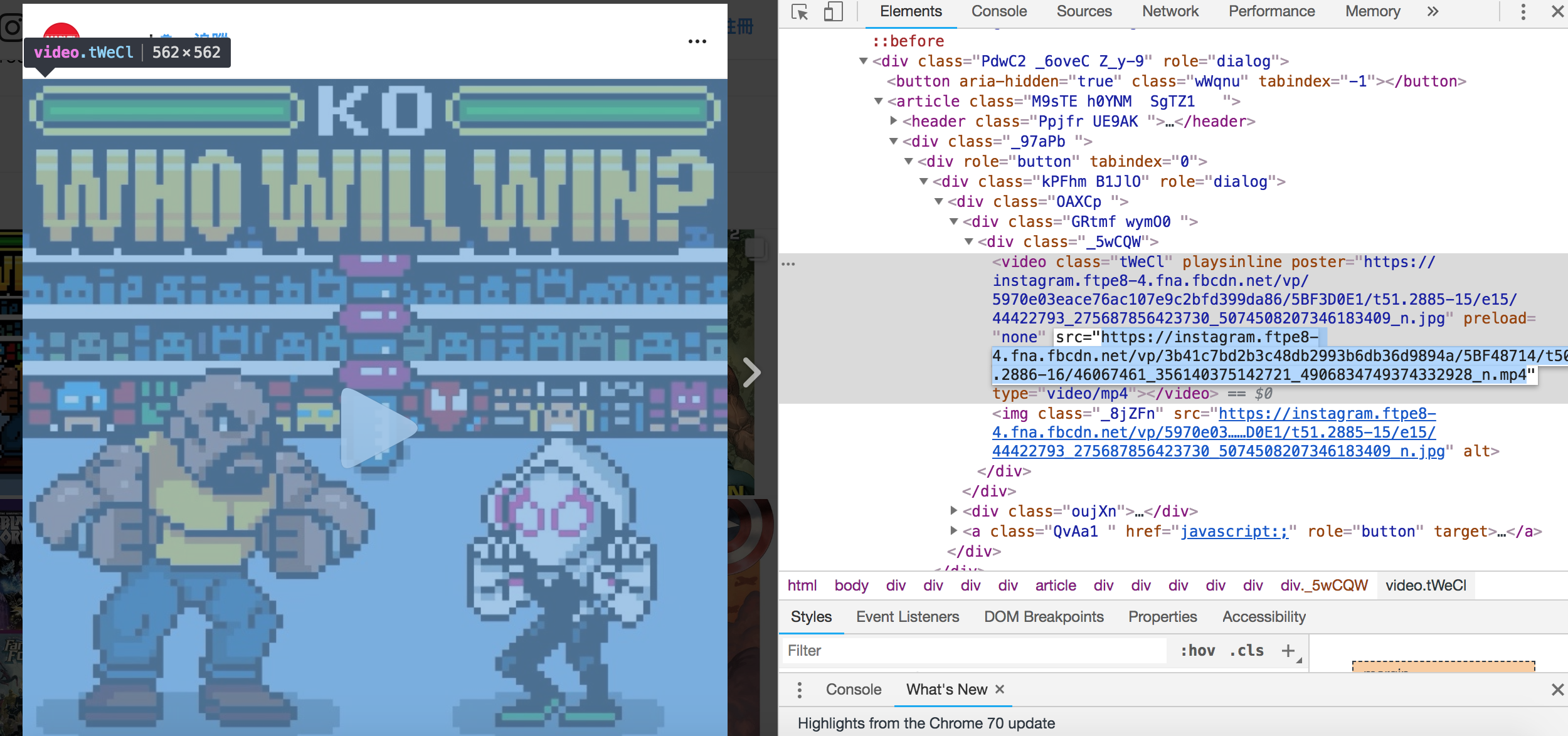
Video 在找到對應的 dom,之後發現並沒有 video 相關的資訊,因為這個頁面只有 Video 的封面,並沒有實際在播放影片,因此必須打開影片的播放頁面,才能找到對應的檔案位置
因此先操作 browser 去打開影片頁面,並爬裡面的 html,發現在 <video class="tWeCl"></video> 裡面
1
| |
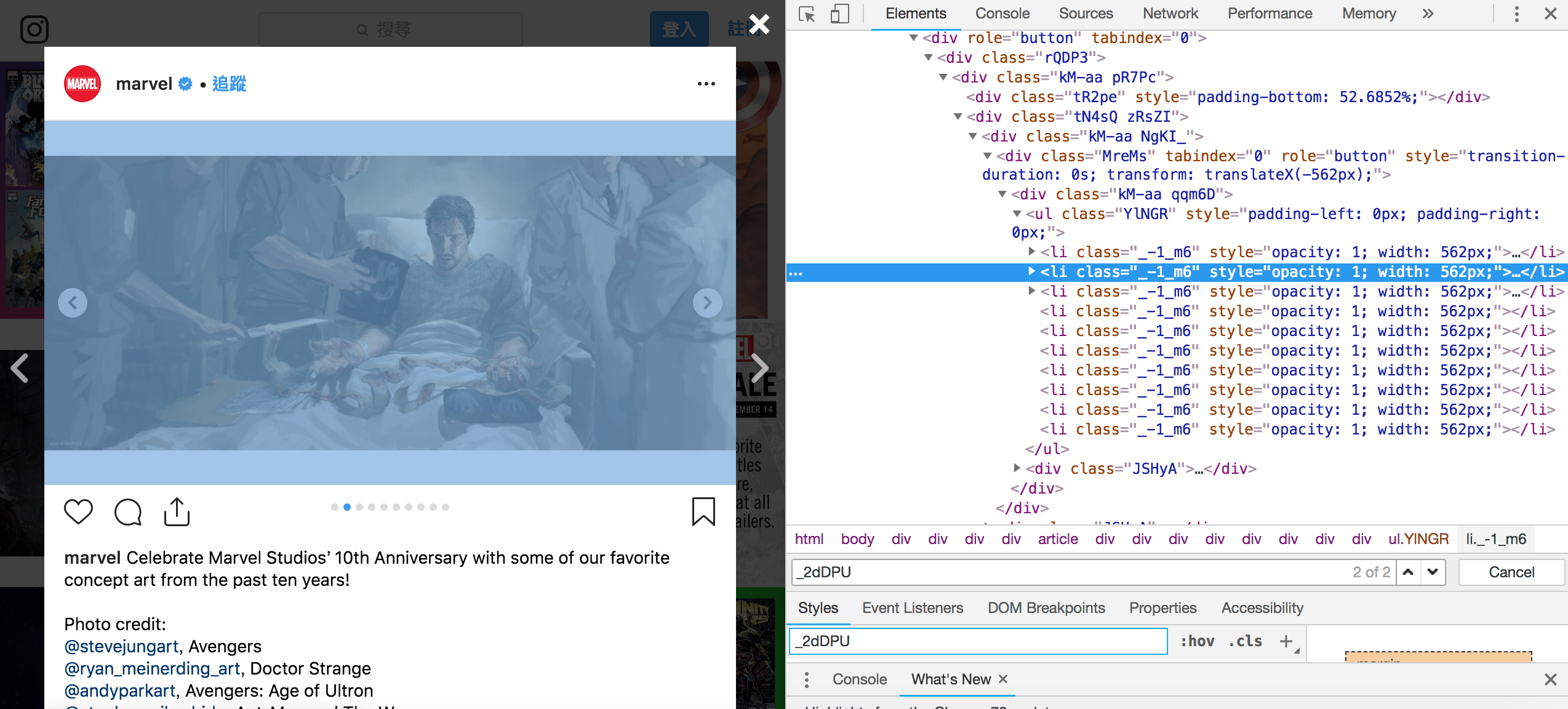
Post
跟 Video,在該頁面只能找到第一張,無法找到後面其他圖片,因此也打開 Post 的頁面去爬,接著找到放在 <li class="_-1_m6"></li> 裡面
1
| |
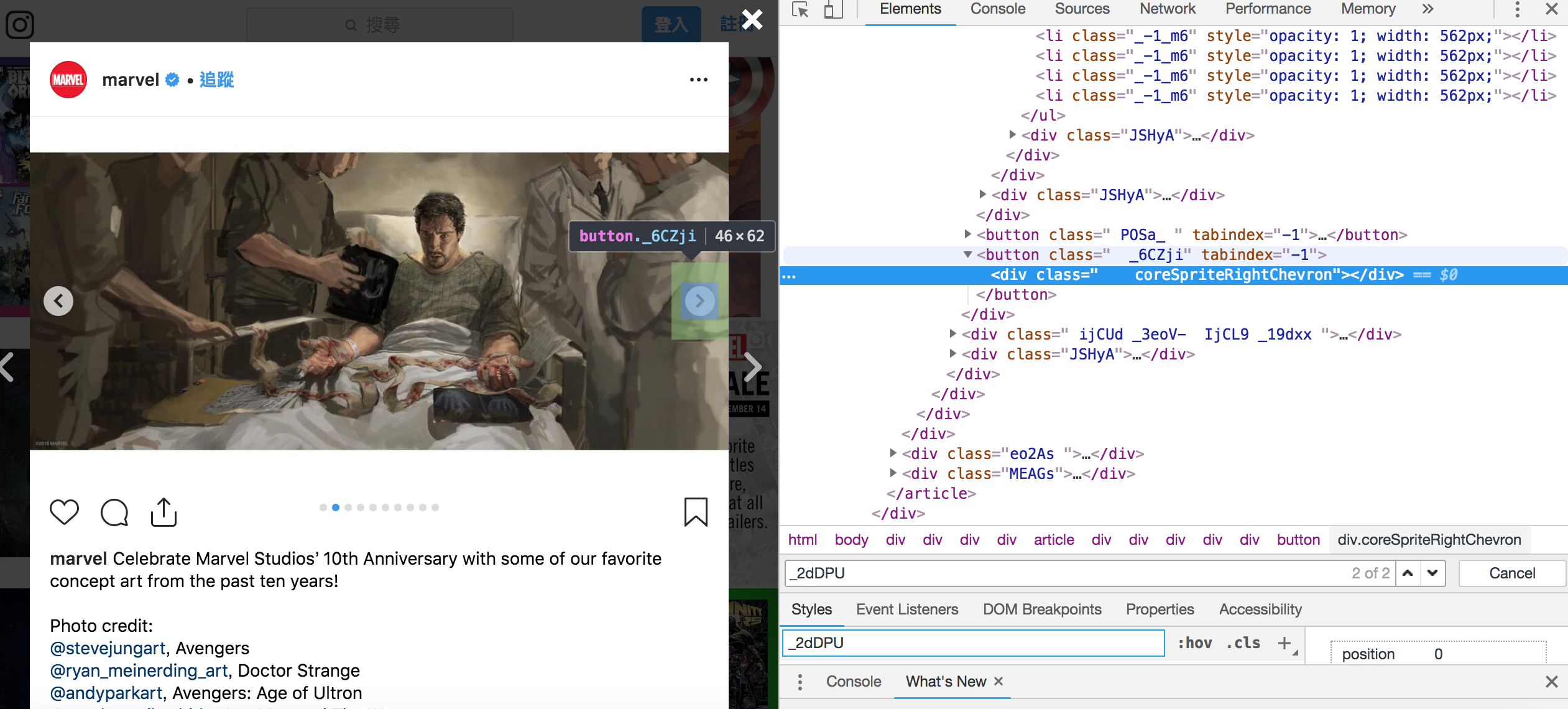
但這邊有個問題,會發現第三個之後,並沒有箭頭可以往下展開,需要點往右的箭頭,滑動圖片,才會接著展開,因此每次都必須點往右的箭頭,一個一個爬,直到最後一張
1 2 3 4 5 6 | |
記得 Video & Post 打開貼文後要關閉才能繼續找下一張!
三. 迴圈
接著會發現上面的 <div class="v1Nh3 kIKUG _bz0w"></div> 數量,跟實際上的貼文數量,是不成比例,但只要往下滑就會發現,div 的數量會不斷增加
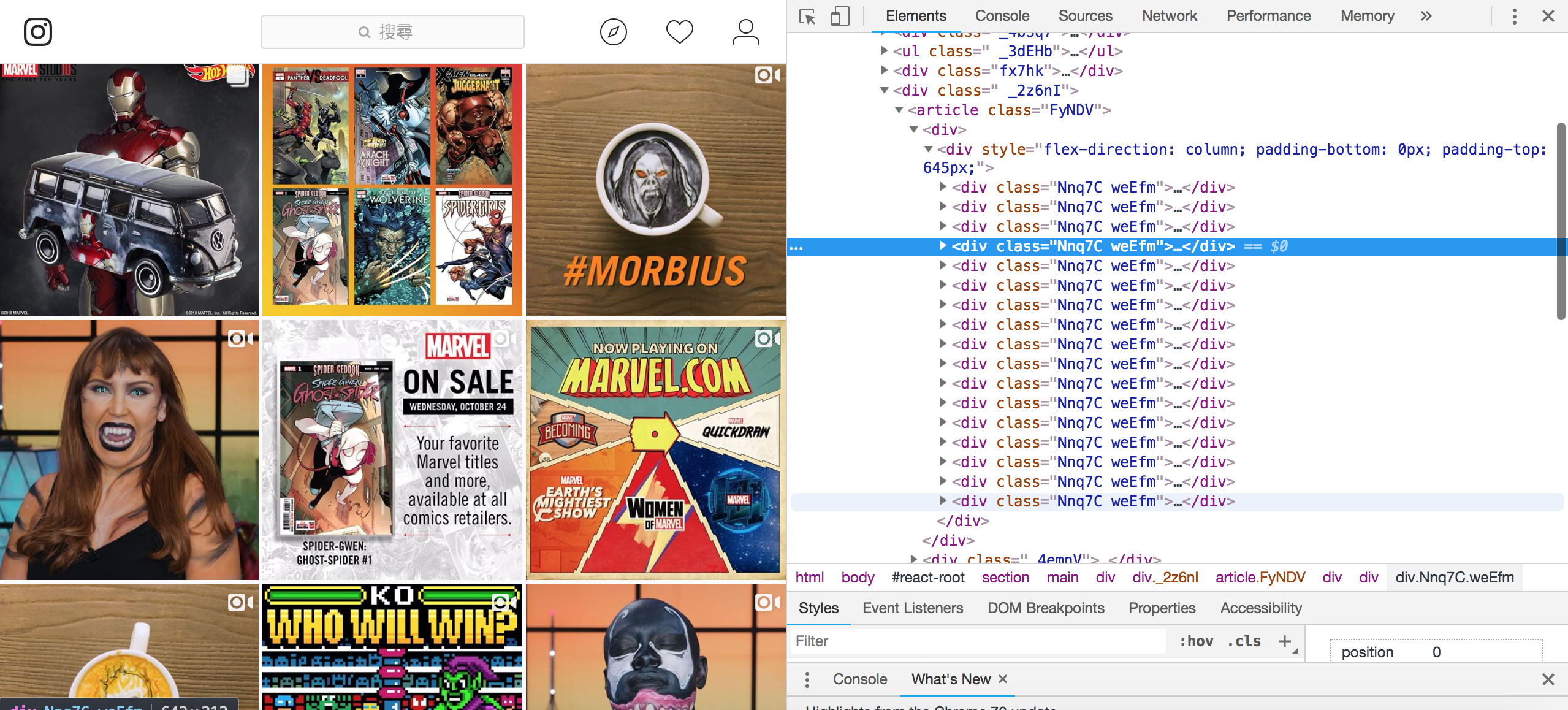
因此接著就是要操作 browser 往下滑到最後,讓頁面載入新的 div 進來
1 2 | |
並且要判斷何時滑到最下面,這邊直接取回頁面的高度,每滑一次,爬完,在滑一次時,判斷是否高度跟上次一樣,一樣就代表已經到最底了
1 2 3 4 | |
接著就是就是無限迴圈直到滑到最下面就停止。
Preview
Other
- 因為是操作 browser 所以跟網路速度會有關係,最好的方式是在每次要讀取新頁面時,先暫停讓頁面讀取再繼續下一步
- 頁面上的 class 都是亂數,可能是透過編譯自行產生,因此下次 Instagram 重新編譯,可能所有的 class 名稱又都不同了..
- 另外如果不希望打開 browser 可以使用 headless 模式
1
| |
example
instagram_crawler_with_selenium
參考文件